Since the solution is posted today, I'll share my solution below.
Problem description is here.
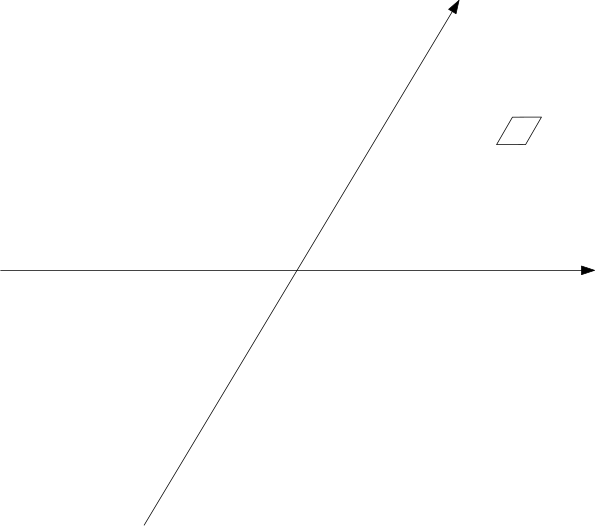
When I saw this problem, the first thing that came to my mind is, to find a proper coordinate system. It's natural to consider the following coordinate system:
where $x$ and $y$ axis make $60^\circ$. The distance from a point at $(i,j)$ to the origin is, $d=\sqrt{i^2+j^2-2ij\cos(120^\circ)}=\sqrt{i^2+j^2+ij}$.
Next, considering the symmetry, we only need to consider the points that's within $30^\circ$ to $x$ axis, or equavalently, from $30^\circ$ to $60^\circ$, i.e. $j\geq i$.
So, our goal is finding all the $r$s such that
$i\geq 1,j\geq i$,
$d=i^2+ij+j^2$ is not a perfect square,
$\lfloor\sqrt{d}\rfloor=r$
has exactly $10^6$ distinct solutions for $d$.
Let's estimate the number of solutions for a given $r$. It's easy to find the density of the points, $2/\sqrt 3$, and the area of the ring is close to $2\pi r$, so there are about $4\pi r/\sqrt 3$ points. If we only consider $1/12$ of the ring, there are $\pi r / 3\sqrt 3\approx 0.6r$ points. But a finite proportion of the points are on the circle, and different points may have the same distance, so the actual ratio should be smaller than $0.6$.
To calculate exactly how many points with different distances are there inside the ring of radius $r$, the range of $i$ is from $\lceil r/\sqrt 3\rceil$ to $r$, and we can find the range of $j$ by solving the quadratic equation. Iterating through them and using a hash set to exclude the duplicate distances, we can find the result.
The first few numbers show that the ratio at arond $r=300$ is about $0.4$. As $i$ and $j$ increase, intuitively, the probability that multiple $(i,j)$ pairs give the same $d$ may increase, so the ratio may decrease slowly. At $r=1000$, the ratio lowers to $0.342$.
But we're not sure how fast it decreases, so it's hard to estimate where exactly we should start at. Typically this kind of estimation can be solved by binary search. A simple binary search gives:
rupper=4313299,rlower=4313298,cnt=1000021
The ratio is about $0.232$. So, the next question is, where exactly should we start at? Let's try $431000$. The first few results are,
r=4310000,cnt=999403
r=4310001,cnt=999559
r=4310002,cnt=999355
r=4310003,cnt=999195
r=4310004,cnt=998994
r=4310005,cnt=999449
r=4310006,cnt=999391
r=4310007,cnt=999828
r=4310008,cnt=998551
r=4310009,cnt=999375
r=4310010,cnt=999272
r=4310011,cnt=999473
r=4310012,cnt=999175
r=4310013,cnt=999477
It seems that it's quite safe to start from here, since although it fluctuates, it's still more or less far from 1000000.
But is that true? Let's see a bit more results...
r=4310052,cnt=999996
r=4310062,cnt=1000173
Damn! This shows the possiblity that we are missing some results that are less than 4310000.
Using a larger range, I got
4305000 -> 998172
4320000 -> 1001878
A 2000 gap seems safe enough, although it's not guaranteed. Let's use this range to start with.
Since the result fluctuates a lot, to find a single solution is not much different from finding all the solutions. We just simply check all the radii in range. But from the hint, it's much easier to find the palindrome solution, since the choices are much fewer. We just need to check 430?034 and 431?134. The result is 4313134.
To find the other solutions, we must check all the 15000 radii. Now, performance becomes an issue. It would take about 13 hours for the python program that I first wrote to complete.
Then I realized that, the numbers are not that huge, they fit in "int" type in C++, and the squares can be stored in a "long long". And indeed, it's much faster.
Then I thought, can I accelerate it further with parallelization? I was thinking of openMP, but while I browse relevant information, I learned that there's class for parallelization in C++17 STL. So, I figured out how to use "std::execution::par" to run the functions in parallel, which sped up the program by a factor of the number of cores, which is 4.
With some simplification to the logic, so that "sqrt()" is only called once in the calculation for each x-coordinate and radius where the rest are all integer operations, I managed to get the result in 5038.41s. The time per each radius is 5038.41s/15000 = 0.336s, really fast. Even without the multi-core parallelization, it would still be about 1.34s per radius, much faster than the speed they show on the solution page.
I also considered GPU acceleration, but apparently I couldn't simply put an STL hash set inside a CUDA kernel. I noticed that there are open source hash set implementations for CUDA, but it's probably not easy to integrate them into google colab. Anyway, I'll look into them when it's necessary.
Since the computation was pretty fast, I ran it again to do some statistics. The results are,
4310930,4311298,4312919,4313134,4313718,
First over:r=4308795,cnt=1000034
Min in range:r=4309083,cnt=998488
Max in range:r=4315454,cnt=1001567
Last under:r=4316001,cnt=999942
, where the first row are the results, "First over" is the first radius whose count is greater or equal to 1000000, "Min in range" is the minimum count after "First over", and "Max in range" is the maximum before "Last under", which is the last radius whose count is below 1000000.
So, this supports the justification to start from 4305000 and end at 4320000, since there are fairly large gaps between them and "First over" and "Last under" respectively. It's unlikely that we're missing a solution outside the range.
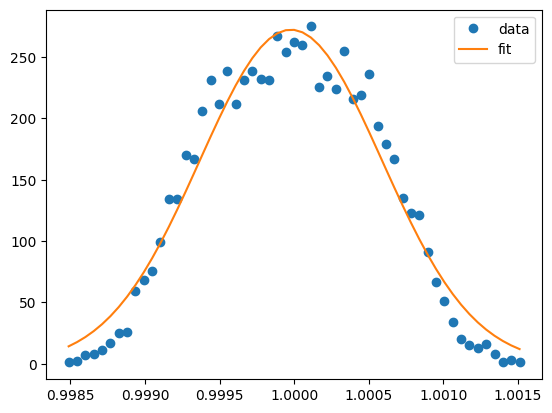
I made a histogram of counts in the range from "First over" to "Last under" and fit it to a normal distribution:
It looks close but there're definitely visible discrepancies. The sudden decrease near the boundary may be due to the cut-off, since if I extend the boundary, there will be more numbers filling in. So it's probably better to exclude the numbers that are close to the boundary. But even without them, the fit is still kind of off. I wonder what kind of distribution it is...
Update with CUDA (2024 01 21):
At first, I considered running multiple radii and sort the result, but it's about 5 times slower (about 7 hours), which is expected because sorting is slow. Then, I thought about counting sort again. It takes much more space and time than a hash set if the numbers only cover a small portion of the range, but it can be easily parallelized. The ratio of squared radii to range is about $\frac{10^6}{(4.3\times 10^6+1)^2-(4.3\times 10^6)^2}\approx\frac{1}{8.6}$. It's not too bad.
Next is to determine how many radii I can run at the same time. If I use long long type, with 128 radii, the range is about $128*2*4320000\approx 2^{30}$ long long numbers, which takes about 8GB. But I just need to store 0 and 1 in the range, and later sum over them to get the count of radii, which is about 10^6*128, still far from the maximum of int type. So, with int type, I can run 200 radii in parallel, which takes about 6.4GB.
Next is to assign the points to the kernel and mark their squared radii to 1. The points are in a long arc of a narrow ring. It's impossible to know where the point should be for a certain thread if I only want to run the points inside the region. So, at first I just precompute all the coordinates, then I can check each of them, since now they're in a one dimension array.
Finally, to find the number of squared radii between two radii, I need to sum over the data in range, so the count at radius r is the difference between the sum at the next radius and the one at this radius, count[$r$]=sum[$(r+1)^2-1$]-sum[$r^2$]. I wondered if there's an efficient algorithm to do this in parallel, but at first I just did a simple summation on CPU.
This version of the program took 5313.97s - it's actually slower, because most of the work was still done on CPU, and there's extra effort to copy data from ram to GPU and back. While the program was running, I thought about how to improve it.
First, I thought about how to do prefix sum in parallel. In a minute, I came up with an O(log n) steps algorithm - but it requires that O(n) threads can run in parallel, which is probably not feasible in many situations. I figured that there must already be research on this, so I searched about it. Apparently what I found was the "Naive Parallel Scan". I looked for the implementation of the efficient algorithm (bank-conflict-free Blelloch algorithm) and noticed that the cub library has this function, and it's included in the cccl.
Next, to get the coordinates of the points in parallel, I must put them in a parallelogram, 60 degrees slanted to the left or to the right. It's impossible to fit them all in the same parallelogram - there's too much empty space, since they are in a very narrow ring. So, I can only take a small portion at a time, and find the parallelogram that covers it entirely. The smaller the height, the less wasted space, but it needs to have enough numbers so that running them in parallel is beneficial.
After all of the above are integrated to the program, this is how it works:
--First I cut the range 4305000 -> 4320000 into steps with step size 200.
----Each region, which is 1/12 of the ring between radius r and r+200, are further cut horizontally where the height is in steps of 128.
------Each piece is extended to a parallelogram, and the coordinates of each point inside the parallelogram is computed in a CUDA kernel, and if the squared radius is in range, it marks the data at that location to 1.
----When all the pieces for a radius step are done, the cub prefix sum function is called to get the summations. Then another cuda kernel reads the summations at the two squared radii for each radius, subtracts them, and writes to the counts.
--Finally the counts are copied to the host and I get the results.
Guess how long did this version of the program take? 88.859s!!! More than 56 times speed up, it took 5.92ms per radius on average. It used about 1G system ram and about 13G GPU ram at peak, because the calculation of prefix sum requires the same amount of space for the destination, which is another 6.4GB.
I learned a lot in the process of writing this program, e.g. the Blelloch algorithm for prefix sum, how to debug cuda functions, etc. And the result is very satisfying!