Leetcode E1822 Sign of the Product of an Array Optimization
I think I’ll stop posting solutions on leetcode discussion because everyone just posts the same stuff there and anything novel doesn’t seem to be recognized, so I’ll just post them here instead. Starting from E1822. Sign of the Product of an Array.
Description:
There is a function signFunc(x) that returns:
1 if x is positive.
-1 if x is negative.
0 if x is equal to 0.
You are given an integer array nums. Let product be the product of all values in the array nums.
Return signFunc(product).
It’s very easy. But can you find the most optimized way to solve it? Comparing with normal approach, a simple modification may speed up your code 70% to 100%.
Code
class Solution {
public:
int arraySign(vector<int>& nums) {
int r=0;
for(int i : nums){
if(i==0) return 0;
r^=i;
}
return r>=0?1:-1;
}
};
edit: So I took a look at the assembly code that the following two codes generate, Code1
int arraySign(int nums[],int len){
int r=1;
for(int i=0;i<len;++i){
if(nums[i]==0) return 0;
r^=nums[i];
}
return r>=0?1:-1;
}
Code2
int arraySign(int nums[],int len){
int r=1;
for(int i=0;i<len;++i){
if(nums[i]==0) return 0;
if(nums[i]<0) r=-r;
}
return r;
}
without optimization:
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -24(%rbp)
movl %esi, -28(%rbp)
movl $1, -8(%rbp)
movl $0, -4(%rbp)
.L5:
movl -4(%rbp), %eax
cmpl -28(%rbp), %eax
jge .L2
movl -4(%rbp), %eax
cltq
leaq 0(,%rax,4), %rdx
movq -24(%rbp), %rax
addq %rdx, %rax
movl (%rax), %eax
testl %eax, %eax
jne .L3
movl $0, %eax
jmp .L4
.L3:
movl -4(%rbp), %eax
cltq
leaq 0(,%rax,4), %rdx
movq -24(%rbp), %rax
addq %rdx, %rax
movl (%rax), %eax
xorl %eax, -8(%rbp)
addl $1, -4(%rbp)
jmp .L5
.L2:
cmpl $0, -8(%rbp)
js .L6
movl $1, %eax
jmp .L8
.L6:
movl $-1, %eax
.L8:
nop
.L4:
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.cfi_startproc
endbr64
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -24(%rbp)
movl %esi, -28(%rbp)
movl $1, -8(%rbp)
movl $0, -4(%rbp)
.L6:
movl -4(%rbp), %eax
cmpl -28(%rbp), %eax
jge .L2
movl -4(%rbp), %eax
cltq
leaq 0(,%rax,4), %rdx
movq -24(%rbp), %rax
addq %rdx, %rax
movl (%rax), %eax
testl %eax, %eax
jne .L3
movl $0, %eax
jmp .L4
.L3:
movl -4(%rbp), %eax
cltq
leaq 0(,%rax,4), %rdx
movq -24(%rbp), %rax
addq %rdx, %rax
movl (%rax), %eax
testl %eax, %eax
jns .L5
negl -8(%rbp)
.L5:
addl $1, -4(%rbp)
jmp .L6
.L2:
movl -8(%rbp), %eax
.L4:
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
with -O1 (same result as -O):
.cfi_startproc
endbr64
testl %esi, %esi
jle .L4
movq %rdi, %rax
leal -1(%rsi), %edx
leaq 4(%rdi,%rdx,4), %rsi
movl $1, %ecx
.L3:
movl (%rax), %edx
testl %edx, %edx
je .L1
xorl %edx, %ecx
addq $4, %rax
cmpq %rsi, %rax
jne .L3
sarl $31, %ecx
movl %ecx, %edx
orl $1, %edx
.L1:
movl %edx, %eax
ret
.L4:
movl $1, %edx
jmp .L1
.cfi_endproc
.cfi_startproc
endbr64
testl %esi, %esi
jle .L5
movq %rdi, %rax
leal -1(%rsi), %edx
leaq 4(%rdi,%rdx,4), %rdi
movl $1, %ecx
.L4:
movl (%rax), %edx
testl %edx, %edx
je .L1
movl %ecx, %esi
negl %esi
testl %edx, %edx
cmovs %esi, %ecx
addq $4, %rax
cmpq %rdi, %rax
jne .L4
movl %ecx, %edx
.L1:
movl %edx, %eax
ret
.L5:
movl $1, %edx
jmp .L1
.cfi_endproc
with -Ofast (same result as -O2 and -O3):
.cfi_startproc
endbr64
testl %esi, %esi
jle .L4
leal -1(%rsi), %eax
movl $1, %edx
leaq 4(%rdi,%rax,4), %rcx
jmp .L3
.p2align 4,,10
.p2align 3
.L12:
addq $4, %rdi
xorl %eax, %edx
cmpq %rcx, %rdi
je .L11
.L3:
movl (%rdi), %eax
testl %eax, %eax
jne .L12
ret
.p2align 4,,10
.p2align 3
.L11:
movl %edx, %eax
sarl $31, %eax
orl $1, %eax
ret
.L4:
movl $1, %eax
ret
.cfi_endproc
.cfi_startproc
endbr64
testl %esi, %esi
jle .L5
leal -1(%rsi), %eax
movl $1, %edx
leaq 4(%rdi,%rax,4), %rsi
jmp .L4
.p2align 4,,10
.p2align 3
.L12:
movl %edx, %ecx
negl %ecx
testl %eax, %eax
cmovs %ecx, %edx
addq $4, %rdi
cmpq %rsi, %rdi
je .L11
.L4:
movl (%rdi), %eax
testl %eax, %eax
jne .L12
ret
.p2align 4,,10
.p2align 3
.L11:
movl %edx, %eax
ret
.L5:
movl $1, %eax
ret
.cfi_endproc
So, indeed code 1 has fewer operations inside the loop, with or without optimization… With optimization, it has 7/10 of the number of operations of code 2 inside the loop, it seems?
So I did some benchmark too,
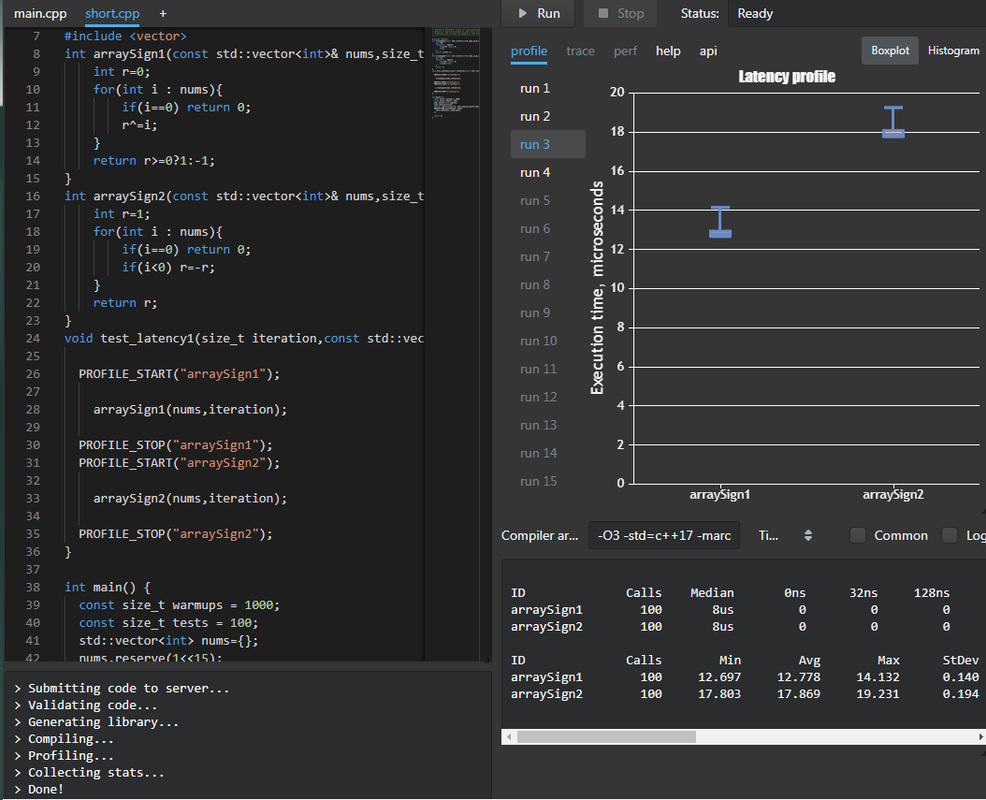
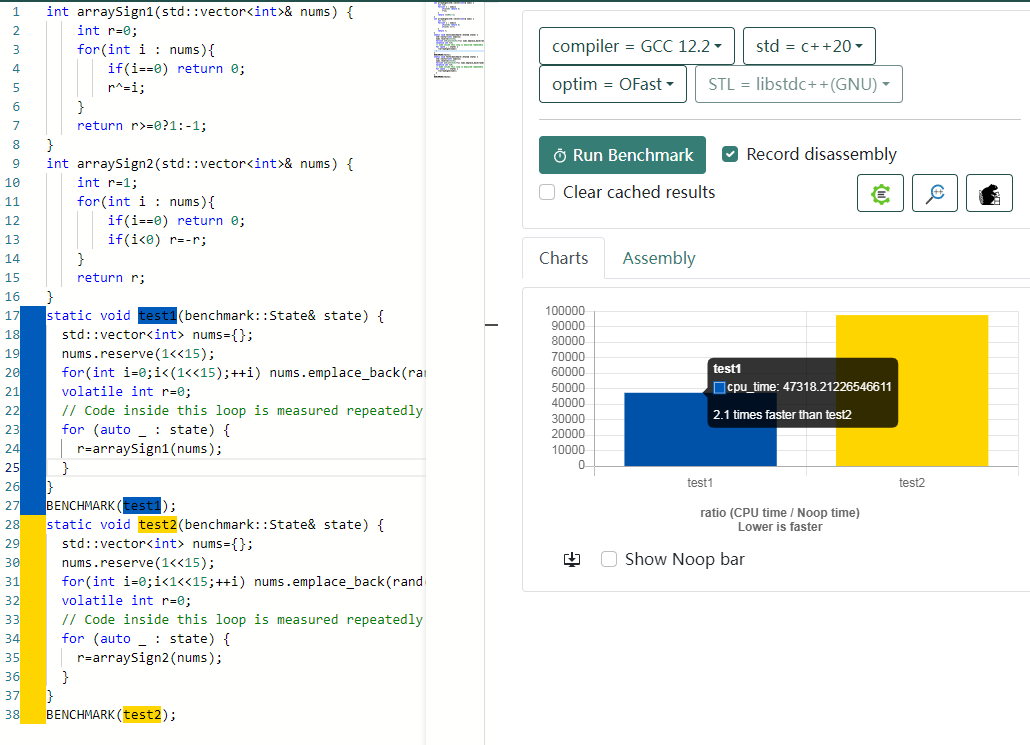
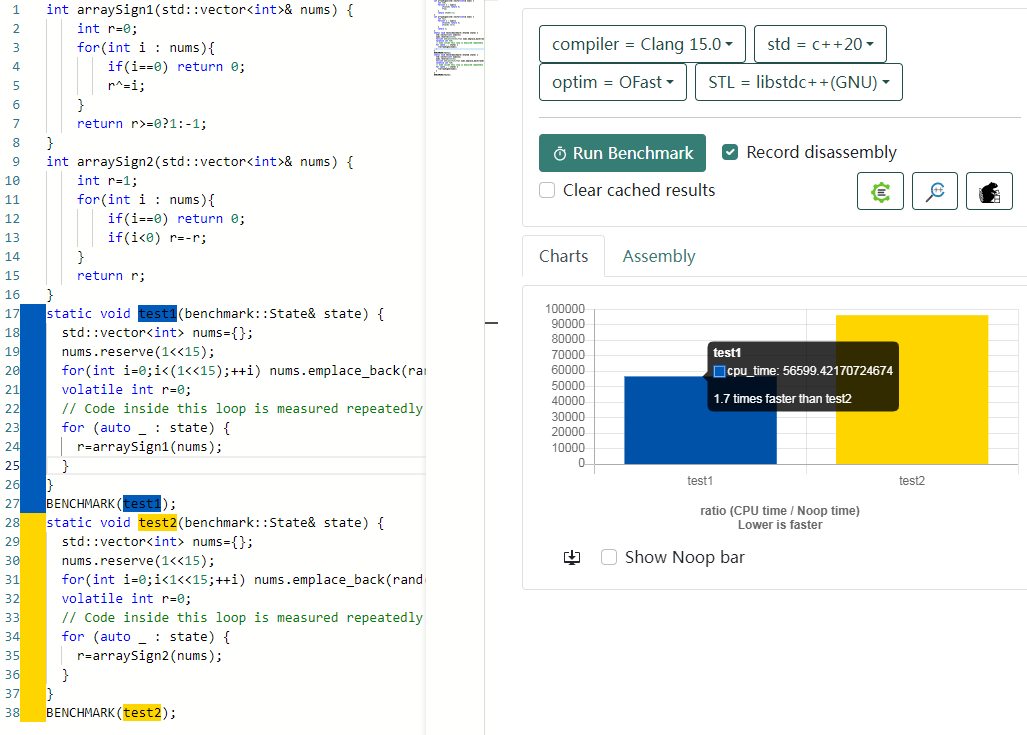 It indeed saves about 30% to 50% time.
It indeed saves about 30% to 50% time.
Further optimization? If the 64bit operation is as fast as 32bit operation and “int” is 32bit, it may seem that using e.g. uint_fast64_t would further halve the time because we can do two “xor”s at the same time. But in this case, it doesn’t help much because checking 0 would be much more complicated. You would have to define two more constants to check if the first half of the 64 bit int is all 0, then the second half. So it probably doesn’t work. I think the code above is pretty much optimized for this problem.